Career-Ops 安裝與設定 — 用 AI 來幫你篩職缺、客製履歷
Search for a command to run...
No comments yet. Be the first to comment.
前言 網路上一大堆都是在介紹如何在 N8N 裡面用 MCP 來呼叫其他工具,但是更多時候我希望 LLM 能直接幫我寫好或是修改 N8N 的工作流程 所以這篇就來介紹如何設定與使用 n8n-mcp-server 來讓 LLM 幫忙操控 N8N 在 GitHub 上有不少的 n8n-mcp-server,經過一下下的簡單搜索,我決定使用這個專案: n8n-mcp-server 原因在於說這個專案的實作提供了基本上所有需要編輯工作流程的功能,以下就來記錄安裝過程 MCP Server 設定 首先當然...
.NET Core Logging- Elmah 02 上一篇我們提到了基本的使用方式,接下來的這一篇我們就來講講要怎麼把 Log 放到不同的儲存體上,以及如何過濾 Log Log 儲存方式 我們先來看這些 Log 倒底存在哪裡,目前共有三種儲存方式,如下: MemoryErrorLog — store errors in memory 預設為使用此方式,簡單來說就是將錯誤 Log 都存在記憶體裡,所以只要應用程式一重新啟動,Log 就沒了;但是也是最方便的方式,只是要注意如果 Log 太...
![[IT 鐵人賽] ASP.NET Core 與 Log 紀錄和追蹤的愛恨交織 - Day 05 - Elmah - 02](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1776070454149%2Fa0702417-5357-4217-a572-7ba53ea36735.png&w=3840&q=75)
.NET Core Logging- Elmah 01 Elmah 是我最一開始使用的 Log 工具,基本上它的功能就是將應用程式所有發生的錯誤記錄下來,不需要改變程式架構,而且又有介面可以觀看,十分的方便;它從 WebForm 時代就有了,到了 MVC 也是運作的很好,那這邊就來介紹一下 Elmah 要如何在 ASP.NET Core 中使用 (.NET Core 也可使用)。 不過很可惜的,目前並沒有釋出官方的 Elmah for .NET Core,不過有一個新專案: ElmahCore...
Azure Data Service - Day 04 - Cognitive Service - Vision - Video Indexer 前面幾篇都是介紹靜態影像的辨識與分析,那這篇就來到針對影片來做處理。 Cognitive Service 針對影片辨識的部分提供了:Video Indexer 它整合了許多功能,在這邊列出一些比較重要的功能: 語系偵測 可以自動偵測出這個影片是屬於哪個語系,目前支援: English, Spanish, French, German, Italia...
![[IT 鐵人賽] Azure Data Service - Day 04 - Cognitive Service - 辨識 - Video Indexer](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1776070473207%2F6423fd4a-4041-4bb2-b918-4cfe3f9aea5e.png&w=3840&q=75)
最近在看新的工作機會,光是瀏覽職缺、比對 JD、調整履歷就花了不少時間。
後來找到 Career-Ops 這個開源專案
作者 santifer 用這套系統篩了 740 多個職缺、產出 100 多份客製化履歷,最後拿到 Head of Applied AI 的 offer。
看起來蠻有意思的,所以我就在 Windows 上實際裝了一輪,這篇就來把整個安裝和設定的過程記錄下來。
我這邊搭配的 AI 後端是 GitHub Copilot CLI。
在開始安裝之前,先簡單介紹一下 Career-Ops 提供了哪些功能:
職缺評估:用 A-F 的評分架構來分析一個職缺值不值得投遞
客製化 PDF:根據每個 JD 的關鍵字,自動調整履歷內容,產出 ATS 友善的 PDF
職缺掃描:可以自動掃 Greenhouse、Ashby、Lever 等平台,內建 45+ 家公司的設定
批次處理:一次評估多個職缺,不用一個一個慢慢跑
申請追蹤:用 Markdown 表格集中管理所有申請狀態
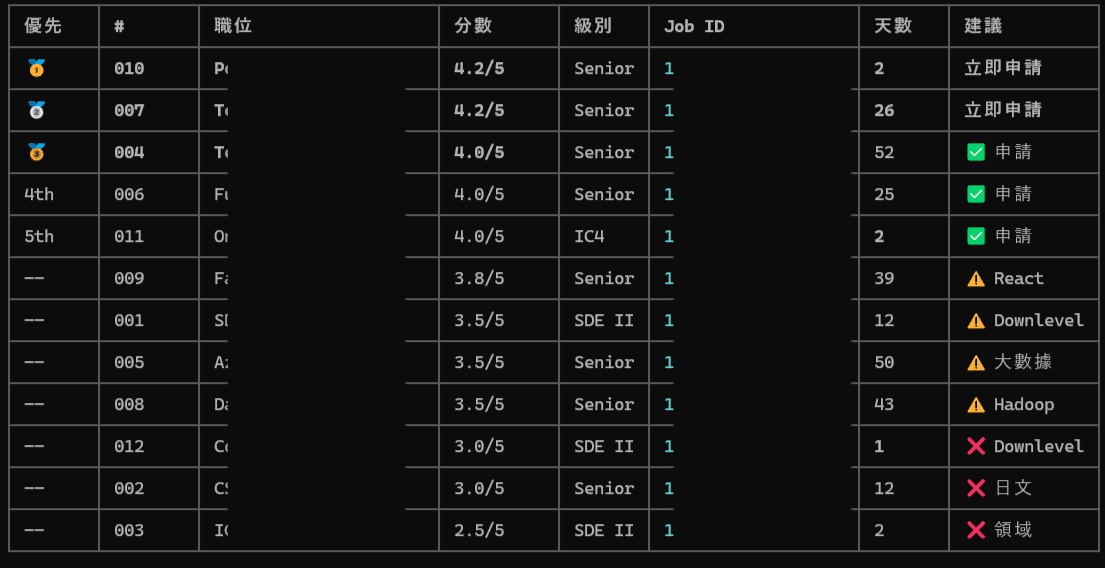
這邊要特別提一下,Career-Ops 的設計理念比較偏向「篩選」而不是「海投」。簡單來說就是幫你從大量職缺中找出值得花時間的那幾個,如果評分低於 4.0/5,系統會直接建議不要投。
我實際跑了 12 個職缺下來,覺得這個門檻設定蠻合理的。
| 工具 | 版本 | 說明 |
|---|---|---|
| Node.js | 18+ | 執行核心腳本 |
| Git | 任意 | Clone 專案用 |
| GitHub Copilot CLI | 最新 | 我這邊使用的 AI 後端,也可以使用任何支援 Skill 的 AI CLI |
| Go | 1.21+(選用) | 編譯 Dashboard 看板,不裝也不影響功能 |
| Python | 3.10+(選用) | 用來把 PDF 履歷轉成 Markdown,使用微軟出的 Markitdown |
首先把專案 Clone 下來並安裝相依套件:
git clone https://github.com/santifer/career-ops.git
cd career-ops
npm install
相依套件蠻少的,就 js-yaml 和 playwright 兩個:
added 4 packages, and audited 5 packages in 15s
found 0 vulnerabilities
Career-Ops 使用 Playwright 來做兩件事:產生 PDF 以及到職缺頁面確認該職缺是否還在開放中。所以這邊需要安裝 Chromium:
npx playwright install chromium
這邊會下載大概 290MB 左右,需要等一下。安裝完成後會顯示下載路徑:
Chrome for Testing (playwright chromium) downloaded to C:\Users\{你的使用者}\AppData\Local\ms-playwright\chromium-xxxx
Chrome Headless Shell downloaded to ...
這邊是整個安裝過程中最重要的部分。Career-Ops 需要先認識你,才能幫你評估職缺和客製化履歷。
首先把三個模板檔案複製出來:
# 複製個人設定模板
cp config/profile.example.yml config/profile.yml
# 複製入口網站掃描器模板
cp templates/portals.example.yml portals.yml
# 複製個人化客製模板(這個檔案永遠不會被系統更新覆蓋)
cp modes/_profile.template.md modes/_profile.md
這三個檔案分別是個人資料、掃描器設定、以及個人化覆寫設定。其中第三個 _profile.md 比較特別,系統更新的時候不會動到它,所以個人的客製化設定放這裡最安全。
接下來打開 config/profile.yml,這是最核心的設定檔,修改成自己的資訊:
candidate:
full_name: "你的名字"
email: "your@email.com"
phone: "+886-XXX-XXX-XXX"
location: "Taipei, Taiwan"
linkedin: "linkedin.com/in/yourprofile"
portfolio_url: "https://yoursite.dev"
github: "github.com/yourusername"
target_roles:
primary:
- "Senior Cloud Engineer"
- "Senior Software Engineer"
archetypes:
- name: "Cloud/Platform Engineer"
level: "Senior/Staff"
fit: "primary" # primary = 夢想職位
- name: "Full Stack Developer"
level: "Senior"
fit: "secondary" # secondary = 不錯的選擇
- name: "Solutions Architect"
level: "Senior"
fit: "adjacent" # adjacent = 延伸嘗試
narrative:
headline: "你的一句話職業標題"
exit_story: "你的獨特故事 — 是什麼讓你與眾不同"
superpowers:
- "你的超能力 1"
- "你的超能力 2"
- "你的超能力 3"
proof_points:
- name: "專案名稱"
url: "https://your-project.dev"
hero_metric: "量化的成果指標"
compensation:
target_range: "TWD 2,000,000-3,000,000"
currency: "TWD"
minimum: "TWD 1,800,000"
location_flexibility: "Taipei preferred, remote-friendly"
location:
country: "Taiwan"
city: "Taipei"
timezone: "Asia/Taipei (UTC+8)"
visa_status: "Local citizen"
這邊有個小細節要注意:archetypes 裡的 fit 欄位分成三種 — primary 代表最想要的目標方向,secondary 是也可以考慮的,adjacent 則是有點距離但願意嘗試看看。系統會根據這個設定來調整評分的權重。
modes/_profile.md這個檔案是用來存放「你自己的規則」的地方,像是:
希望怎麼包裝自己的經歷(敘事框架)
面試時薪資要怎麼談
哪些工作地點可以接受
職位原型的對應方式
這邊有一條重要的規則:個人化的設定放 _profile.md 或 profile.yml,不要去修改 _shared.md。因為 _shared.md 是系統檔,更新的時候會被覆蓋掉。
Career-Ops 需要一份 Markdown 格式的 cv.md 來當作所有評估和 PDF 產生的資料來源。
# 方法 1:手動建立
# 直接建立 cv.md,用 Markdown 格式撰寫你的履歷
# 方法 2:從 PDF 轉換(需要 markitdown)
pip install "markitdown[pdf]"
python -m markitdown your-cv.pdf > cv.md
我這邊手上有現成的 PDF 履歷,所以直接用 markitdown 來轉換。這個工具是 Microsoft 出的,轉出來的格式還不錯:
# 安裝 markitdown(含 PDF 支援)
pip install "markitdown[pdf]"
# 轉換你的 PDF 履歷
python -m markitdown path/to/your-cv.pdf > cv.md
要注意的是轉完之後建議自己檢查一下,有些格式可能會跑掉,特別是表格和多欄排版的部分。主要確認以下幾個區段有正確抓到就好:Professional Summary、Work Experience、Technical Skills、Projects、Education、Certifications。
如果也有在用 VS Code 或 Copilot CLI 的話,可以把 markitdown 設成 MCP server,這樣之後可以直接在對話中叫它轉檔:
pip install "markitdown[mcp]"
在專案中建立 .vscode/mcp.json:
{
"servers": {
"markitdown": {
"type": "stdio",
"command": "python",
"args": ["-m", "markitdown.mcp"]
}
}
}
專案有內建一個 doctor 指令,跑一下就可以知道哪裡還有問題:
npm run doctor
全部打勾就代表可以開始使用了:
career-ops doctor
================
✓ Node.js >= 18 (v24.13.1)
✓ Dependencies installed
✓ Playwright chromium installed
✓ cv.md found
✓ config/profile.yml found
✓ portals.yml found
✓ Fonts directory ready
✓ data/ directory ready
✓ output/ directory ready
✓ reports/ directory ready
Result: All checks passed. You're ready to go!
如果有 ✗ 的項目,它會告訴你要怎麼修,修完再重跑一次即可。
我這邊是在專案目錄中開啟 Copilot CLI,最直接的用法就是貼一個職缺 URL 進去:
# 貼上職缺 URL,系統會自動執行完整 pipeline
https://apply.careers.microsoft.com/careers/job/xxxxx
貼進去之後它就會自動跑完整個流程 — 抓 JD、評估、產生報告、製作 PDF、更新追蹤器,全部自動完成。也可以透過指令單獨執行特定功能:
career-ops # 顯示所有可用指令
career-ops scan # 掃描入口網站
career-ops pdf # 產生 ATS 優化 PDF
career-ops tracker # 查看申請狀態
career-ops batch # 批次評估多個職缺
如果使用的是 Claude Code:
claude # 在專案目錄中啟動 Claude Code
透過 slash 指令來操作:
/career-ops # 顯示選單
/career-ops scan # 掃描入口網站
/career-ops pdf # 產生 PDF
那接下來就來看看貼一個 URL 進去之後到底會發生什麼事。整個流程如下:
透過 Playwright 或 WebFetch 去抓取 JD 內容
執行 A-G 七個區塊的完整評估
將評估報告儲存到 reports/
根據 JD 關鍵字重新編排履歷,產出 ATS 友善的 PDF
在 data/applications.md 新增一筆追蹤紀錄
我第一次跑的時候蠻驚訝的 — 一個 URL 貼進去,幾分鐘之後就產出了一份完整報告、一份客製化 PDF,還自動更新了追蹤表。
每份報告包含七個區塊,下面來一一介紹:
| 區塊 | 說明 |
|---|---|
| A) 角色摘要 | 快速瀏覽這是什麼類型的職位、級別、是否支援遠端 |
| B) CV 匹配 | 把 JD 的每個需求拿出來,逐一對照履歷中的對應經歷,有匹配的標記、沒有的會告訴你怎麼補 |
| C) 等級策略 | 如果 JD 的職級比你低,會提供「如何避免被降級」的談判建議 |
| D) 薪資研究 | 從 Glassdoor、Levels.fyi 抓取即時薪資數據,附上資料來源 |
| E) 客製化計畫 | 針對這個職缺,列出 CV 和 LinkedIn 各自 Top 5 的修改建議 |
| F) 面試準備 | 準備 6-10 個 STAR 故事,直接對應 JD 的需求 |
| G) 職缺真實性 | 判斷這個職缺是否為真實開放中的機會,還是所謂的幽靈職缺 |
career-ops/
├── cv.md # 你的履歷(必要)
├── config/profile.yml # 你的個人設定(必要)
├── modes/_profile.md # 你的客製化(不會被更新覆蓋)
├── portals.yml # 掃描器設定(建議)
├── data/applications.md # 申請追蹤器
├── reports/ # 評估報告(自動產生)
├── output/ # PDF 檔案(自動產生)
├── modes/ # 技能模式(系統檔案)
│ ├── _shared.md # 共用系統設定
│ ├── oferta.md # 單一職缺評估
│ ├── pdf.md # PDF 產生
│ ├── scan.md # 掃描器
│ └── ...
├── templates/
│ ├── cv-template.html # ATS 優化 CV 模板
│ └── states.yml # 標準狀態定義
└── batch/ # 批次處理
這邊蠻重要的,Career-Ops 把檔案分成兩層:
使用者層(系統更新時不會動到):
cv.md、config/profile.yml、modes/_profile.md
portals.yml、article-digest.md
data/*、reports/*、output/*、interview-prep/*
系統層(更新時會覆蓋,不要放個人資料):
modes/_shared.md、modes/oferta.md 等系統模式檔
CLAUDE.md、*.mjs 腳本、templates/*
簡單來說就是:個人化設定放 _profile.md 或 profile.yml,不要去修改 _shared.md。
Career-Ops 有一個我覺得設計得蠻好的地方:它的設定檔都是 Markdown 和 YAML 格式,AI 可以直接讀取也可以直接修改。所以不需要自己去翻文件找設定在哪裡,直接用自然語言跟 AI 講就好:
| 想做的事 | 跟 AI 說 |
|---|---|
| 改變目標職位類型 | "把 archetypes 改成後端工程師相關的角色" |
| 翻譯模式檔案 | "把所有 modes 翻譯成繁體中文" |
| 新增掃描公司 | "在 portals.yml 加入 Google、Apple、Meta" |
| 修改評分權重 | "把薪資維度的權重調高" |
| 更新履歷 | "用我剛貼的內容更新 cv.md" |
| 修改 CV 模板設計 | "把 CV 的配色改成藍色系" |
實際使用了一段時間之後,有幾個地方值得注意:
系統不會自動幫你送出申請。它會協助填表、撰寫回答、產生 PDF,但最後按下送出的動作一定是由自己來完成。這點我覺得設計得很好。
評分低於 4.0 的職缺建議就不要投了。我跑了 12 個職缺,4.0 以下的確實都有明顯不合適的地方,硬投反而浪費時間。
認真準備投 5 家,比亂投 50 家來得有效。
AI 偶爾會產生不正確的資訊,特別是薪資數據和公司資訊的部分,提交之前記得自己再確認一下。


這套系統在剛開始使用的時候評估不會太準確,因為它對你的了解還不夠。多跑幾次、多給它一些回饋(像是「這個分數太高了,我不會投這種」),它會越來越準。我大概到第五、六個職缺的時候,就覺得它的判斷跟我自己的直覺差不多了。
如果你也在找新的工作機會,推薦可以試看看。
參考連結: